Dither and noise-shaping



|
Dither and noise-shaping |
|
|
Atlas can dither or noise-shape its digital output to produce high-quality 16 bit output (for, say, a CD master) from 20 bit or 24 bit recordings. This section discusses the principles and choices involved in word-length reduction.
Truncation and dithering There are many points in a digital audio signal path where precision can be lost. For example, in a digital transfer from 24-bits to 16-bits, or in an analogue to digital conversion. In this situation it is not sufficient just to discard low-order bits this causes truncation distortion, characterised by aharmonic frequency components and unnatural, harsh decays.
Instead, it is preferable to use some sort of dithering process, whereby the truncation process is linearized by modulating the signal prior to the truncation, usually by the addition of a small amount of noise. By adding a random element to the truncation decision, small components as far as 30dB below the noise floor can be accurately represented, and an analogue-like low-signal performance can be realised. This is achieved at the expense of slightly raising of the noise floor, although with some dithering schemes such as noise-shaping, linearization can be achieved with no noticeable increase in noise.
How can dithering allow information to be preserved below the least-significant bit? It seems impossible. Consider a simple example where the audio samples are numbers between one and six, and we are going to truncate them (i.e. reduce their resolution) so that numbers from one to three become zero, and those from four to six become one. Clearly much information will be lost, and all excursions of the signal between one and three and between four and six will not affect the output at all. But if we throw a die for each sample, add the number of spots to that sample, and translate totals of six and below to zero and totals of seven and above to one, we have a simple dithering scheme. Input samples of three will be more likely to result in outputs of one than will inputs of one. The throw of the die is our dither noise. Since all the faces of the die have an equal chance of occurring, this is known as rectangular probability distribution function (RPDF) dither, which in fact does not produce perfect linearization. We actually use triangular probability distribution function (TPDF) dither, which is like throwing two dice with a resultant increase in the probability of medium sized numbers totals of two and twelve occur much less often than seven.
Noise shaping
It is possible to reduce the subjective effect of the added dither noise by either using spectrally weighted ('blue') dither noise, which is quieter in the more sensitive registers of the ear, or by an even more effective technique called 'noise shaping.
Noise shaping is just like conventional dithering, except that the error signal generated when the unwanted low-order bits are discarded is filtered and subtracted from the input signal. You cant get something for nothing the error cannot be simply cancelled out, because we already know that the output hasnt got enough bits to precisely represent the input. But by choosing an appropriate shape for the error filter, we can force the dither noise / error signal to adopt the desired shape in the frequency domain we usually choose a shape which tracks the low-field perception threshold of the human ear against frequency. As can be seen from the plots below, this has the effect of actually lowering the noise floor in the more sensitive frequency bands when compared to the flat dither case.
The theory of noise shaping has been around for a long time certainly since well before DSP in real-time was feasible for audio signals. It has applications in many signal processing and data conversion applications outside audio. It has been well researched, and is not in the least bit mysterious. Proprietary word-length reduction algorithms are generally conventional noise shapers. Assuming that the basic implementation and dither levels are correct, the only significant freedoms available to the designer are to choose the actual shape of the noise floor, and to decide how to adapt this (if at all) to different sample rates.
Prism Sound SNS (Super Noise Shaping)
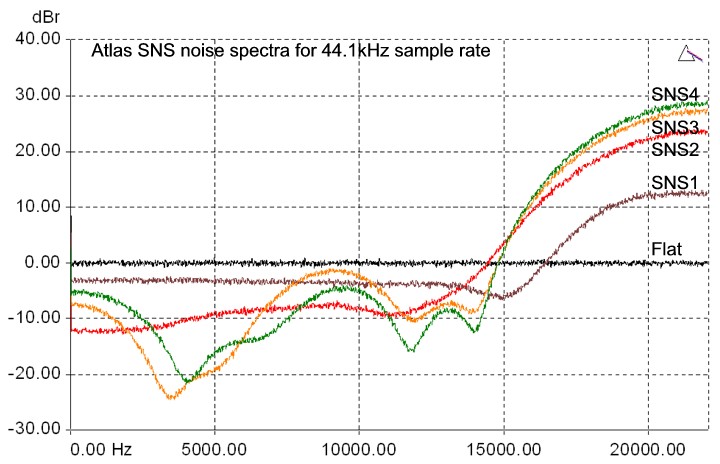
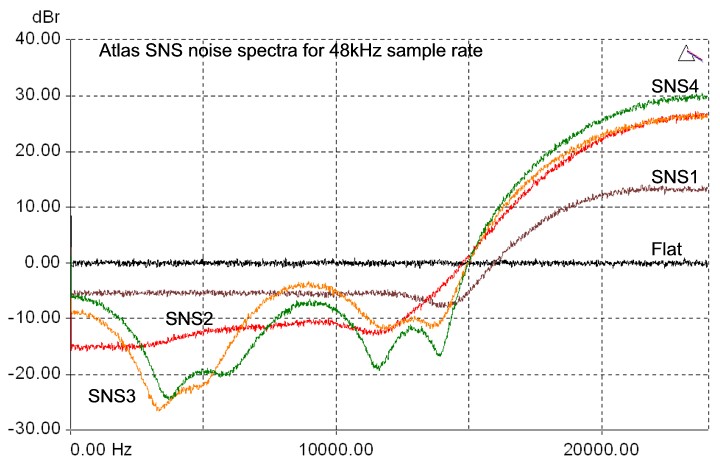
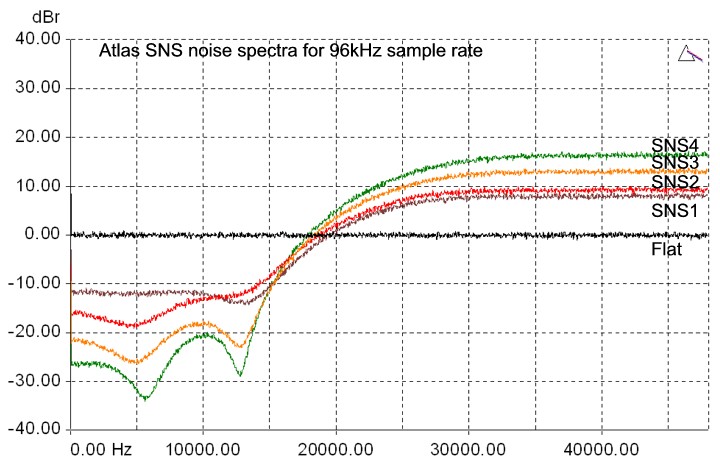
Atlas provides a comprehensive choice of dithering and noise-shaping processes. These comprise flat dithering, plus a selection of four Prism Sound SNS (Super Noise Shaping) algorithms. All produce high-quality 16 bit output: the choice of which one to use is purely subjective. The four SNS algorithms are designated SNS1 to SNS4, in increasing order of the degree of shaping. The spectra of the four SNS algorithms are shown below. Note that, unlike some noise shaping algorithms, SNS spectra are adjusted automatically to provide optimum subjective advantage at each different sample rate. The spectra are shown below for 16-bit output, at 44.1kHz, 48kHz and 96kHz sample rates.
It is difficult to assess the difference in sound between different noise shapers for any given program material, since their effects are at very low amplitudes (the 0dB line on the plots below represents flat dither with an rms noise amplitude of about 93.4dBFS). It is tempting to audition noise shapers by using a low signal level and boosting the shaper output by tens of dBs in the digital domain prior to monitoring. Using this method it is easy to hear that the noise floor of more extreme shapers is clearly not white switching, say, from SNS1 to SNS4 sounds like shhhhh..ssssss as the noise is shifted towards the higher frequencies. However, this is not really a meaningful test since the sensitivity of the ear at different frequencies is very dependent on level, and the design of the more extreme shapers is in any case intended to render the noise floor completely inaudible at normal listening levels. Ultimately, the only right choice of noise shaper is the one which sounds best for the material. SNS2 is a good starting point for most situations.
The Prism Sound SNS logo shown above is found on many of the worlds finest CDs, and is recognised as a standard of technical excellence. The logo, and accompanying sleeve note, is available by contacting sales@prismsound.com.
|